
A Simple and Robust Convolutional-Attention Network for Irregular Text Recognition
15 May 2019 | ml ocr읽어보니 Transformer를 가져다 쓴게 거의 전부임.. 읽은게 아까워서 간단히 정리하고 넘어가자!
Overview
- irregular text를 인식하는 문제를 다룸
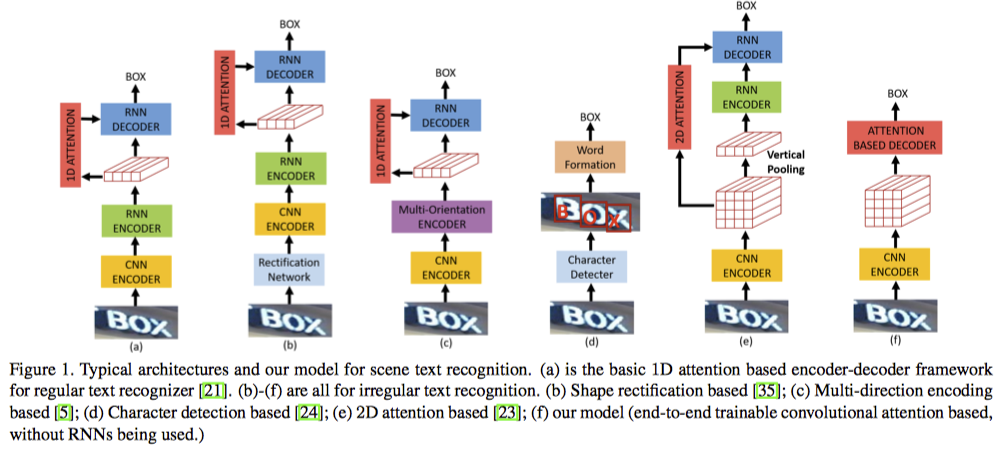
- 가장 기본이 되는 구조
- Rectification Network를 사용하여 이미지를 펴는 모듈이 추가
- 심하게 distortion이 있거나 curved shape에 대해서 잘 안됨
- 여러 방향으로 encoding
- redundant representation
- character 단위로 detection, recognition
- 돈이 없다.
- 2D attention과 sequence modeling을 같이…
- 딱히 단점을 말하지 않음.
자기 논문이라서..?
- 딱히 단점을 말하지 않음.
- sequence modeling 없이 2D attention만. 논문의 모델
letter listing을 markdown이 지원하지 않는다. a=1로 생각하고 보자…
Model
주장
- irregular text는 2D space에 퍼져있는데, 이를 1D sequence로 모델링하는 것은 부적절하다.
- RNN은 sequential하게 학습하기에 병렬 학습이 어렵다
- 이건 transformer에서 그대로 가져온 내용이니 무시!
Model
- 이건 transformer에서 그대로 가져온 내용이니 무시!
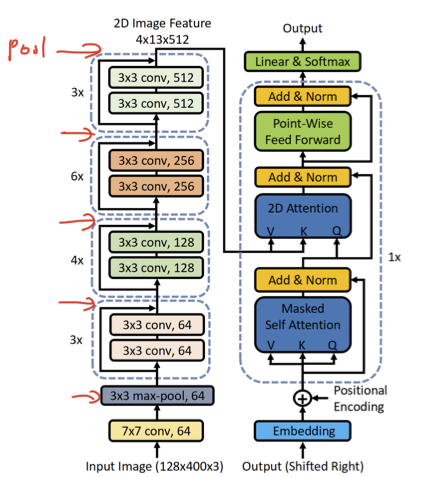
- Sequence modeling 부분을 전부 없애고
- CNN feature를 2D인 상태 그대로 attention하여 decoding
- decoder는 layer를 1개만 썼으며, 나머지 parameter는 transformer decoder와 동일
- 이미지가 (128 x 400 x 3) 로 4배를 키움
이래야 잘됐겠지…
Experiments
Number of Decoder Blocks

- 1개만 써도 충분히 잘되더라..
- 여러 layer를 써보면 마지막 layer만 제대로 attention을 하더라..(위의 3개)
- 여러 layer에 auxiliary prediction을 주면 모두 attention을 잘 함 (아래 3개)
E.T.C
- number of attention heads
- 8개가 제일 좋더라
- self attention의 중요도
- encoder에는 붙여도 효과가 별로 없고, decoder에는 있는게 좋더라
- 이건 사실 좀 애매해보이는데.. encoder에만 붙여도 ffn layer 빼고는 같지 않을까?
Comparision with State-of-the-art
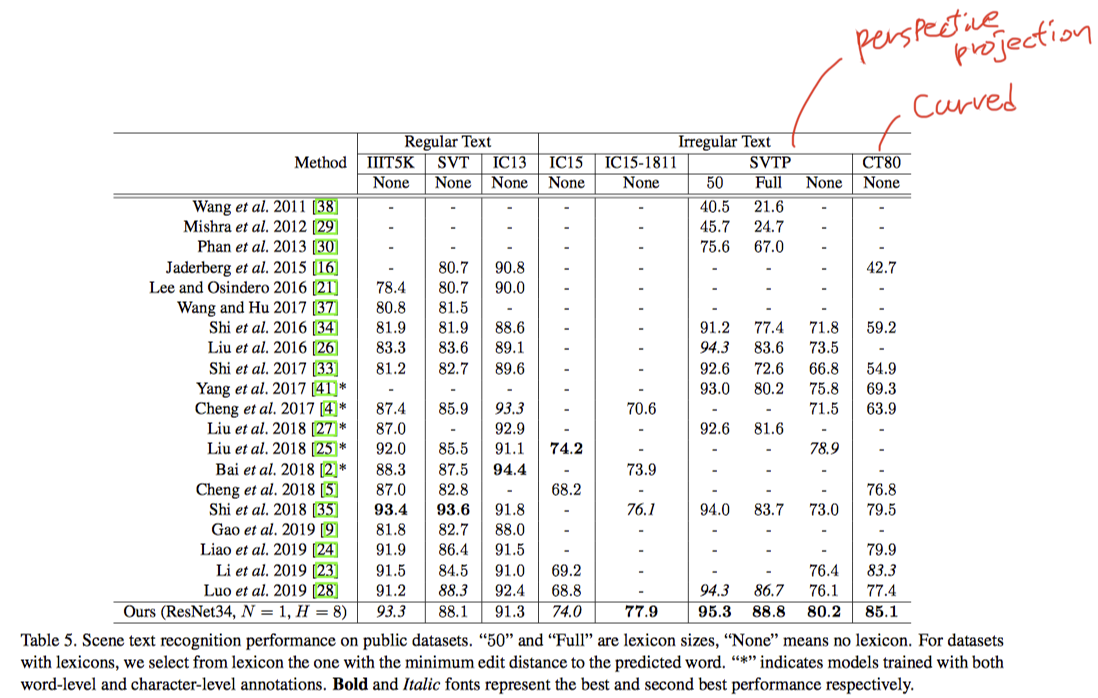
- irregular text dataset의 6개 중 5개에 대해서 제일 잘했다.
- 나머지 하나는 character level로 학습한것이 가져감.
- [23], [35] 보다 훨씬 빠르다.
- training time/ inference time 모두일까..? 제대로 안나와있다..
Robustness

- 여러가지 옵션으로 이미지를 구겨봤는데 그래도 잘하더라…