
Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement
26 Feb 2018 | ml nmt- 저자
- Jason Lee, Elman Mansimov, Kyunghyun Cho
2. Non-Autoregressive Sequence Modeling
standard sequence modeling
- 먼저 sequence를 modeling하는 방법 중 Autoregressive model에 대해서 설명한다.
- sequence $Y = (y_1,…,y_t)$에 대해서,
- $log\ {p(y_t \vert y_{<t})} = f_\theta(y_{<t})$
- 요런 식으로 디자인하고, $f_\theta$는 RNN 종류를 쓰는 것이 standard LM이다.
- 즉, 이전 step 들에 conditional하게 디자인을 한다!
- 만약 번역과 같이 extra conditioning variable(X)이 들어가면
- $log\ {p(Y \vert X)}$ 꼴로 변하게 될 것이다.
limitation
- 위처럼 autoregressive한 모델은 디코딩할 때 문제가 된다.
- $\hat{Y} = {argmax}_Y log\ p(Y \vert X)$ 를 뽑으려면,
- condition이 자기 앞 step에 붙기 때문에,
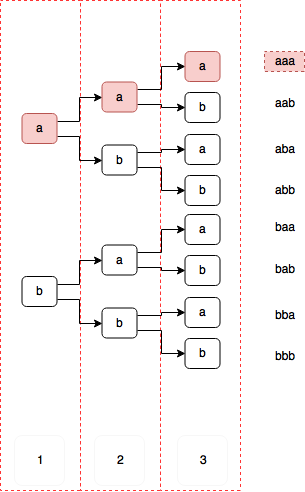
-
vocab이 a, b만 있을 경우, 3-step까지 확률을 구하기 위한 그림
- 모든 경우의 수를 봐야하며, 이는 vocab-size의 non-polynomial 시간이 걸린다.
- 이래서 어느정도 polynomial한 시간에 풀기 위해
- Greedy search: 매 스텝에 가장 확률이 높은것을 바로 뽑음
- Beam search: pool size(width)를 정해서, 그만큼만 풀을 유지하며, 뽑아내는 방식.
- Greedy search: 매 스텝에 가장 확률이 높은것을 바로 뽑음
- 으로 근사시켜서 풀어버린다. -> Decoding Gap
Non-autoregressive model 소개
- 최근에 나온 Non-autoregressive model은 step들이 모두 independent하다고 보고 풀어버린다.
- $P(Y \vert X) = \Pi_t^Tp(y_t\ \vert\ X)$
- 요렇게하면, conditionally independent니까, 한번에 뽑는 것이 가능하며, 근사시킬 필요도 없다!
Modeling Gap V.S. Decoding Gap
- 근데, target variable들간의 잠재적 dependency가 network에 잘 반영되어야하는 문제가 있다.
- 이 것을 논문에서는 potential modeling gap으로 정의함.
- 그래서 NA는 A보다 modeling gap이 큰 대신, decoding은 아까 말한대로 polynomial에 optimal solution을 찾으며, 따라서 gap이 존재하지 않는다.

3. Iterative Refinement for Deterministic Non-Autoregressive Sequence Modeling
3.1 Latent variable model
Modeling 및 lower bound 찾기
- 위에서 target variable들 간의 potential dependency를 잘 잡는 것이 핵심이라 했기 때문에, 요걸 잘 잡는 것을 목표로 구현했겠지…
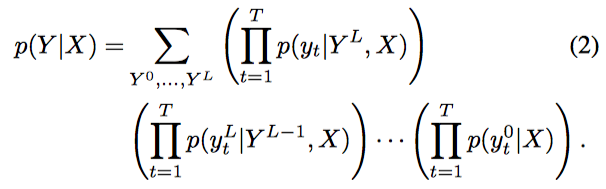
- L개의 R.V.를 만들어서 marginalize를 하도록 한다.
- 근데, 당연히 위의 식은 intractable하다!
- 요럴 때, 우리가 자주 쓰는 트릭… Lower bound를 구해서 높이기…
- L=1이라고 가정하면 요런 식으로 된다..
- L=1이라고 가정하면 요런 식으로 된다..
- 최종적으로 lower bound는 다음처럼 된다.
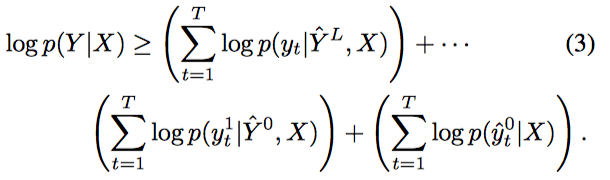
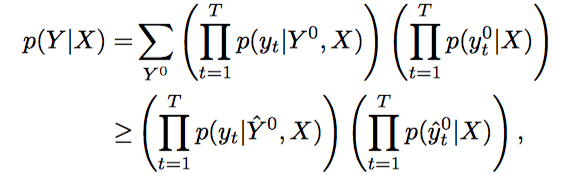
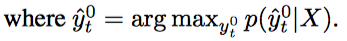
RV 잡기
- L개의 RV를 마음대로 잡을 수 있었지만, 뉴럴 네트워크를 공유해서 쓰고싶었고, 그래서 output Y와 같은 타입으로 한정지음
- 그러면 $p(Y^l \vert \hat{Y}^{l-1}, X)$를 한 decoding step으로 만들 수 있다.
- 또한 parameter를 sharing하는 것을 통해 adaptive refienment step 결정이 가능했다고한다.
Training
- trainig pair: $(X, Y^*)$ 에 대해
- (3)번 식을 계산한다.
- 그리고 다음 식을 minimize한다.
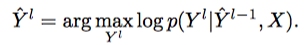
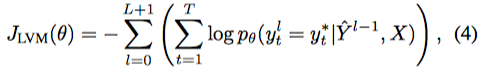
3.2 Denoising Autoencoder
- 여기서 만든 모델이 Conditional denoising autoencoder의 학습과정으로 볼 수 있다고 한다.
- Corruption process: $C(Y \vert Y^*)$
- 정확한 output $Y^*$에 noise를 섞음
- $\tilde{Y} \sim C(Y \vert Y^*)$를 sample함.
- 각 $\tilde{Y}$는 (2)번 EQ의 input으로 할 수 있음.
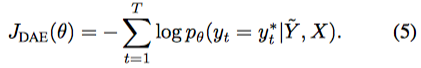
- 위의 식을 minimize 하는 것이 목적!
- 이 논문에 나온 대로 Corruption Process를 진행했다네…
- $Y^=(y_1^, … , y_T^*)$의 각각의 element에 대해서,
- $\beta \in [0, 1]$의 확률로 corruption을 결정
- $y_{t}^*$를 corruption하기로 하면
- $y_{t+1}^* \leftarrow y_t^*$로 대체하고
- $y_t^*$를 vocab에서 uniform random으로 교체 하거나
- $y_{t+1}^* \leftrightarrow y_t^*$로 swap
- 위와같은 프로세스를 sequentially 진행한다.
3.3 Training
- 실제 트레이닝은 앞에서 본 $J_{LVM}$과 $J_{DAE}$를 같이 섞어서 썼다.
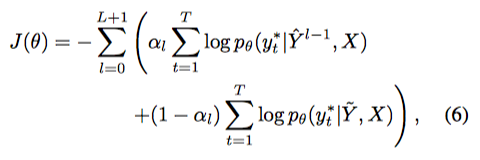
- $\alpha_l \sim p_{DAE} \in [0,1]$: bernoulli distribution $p_{DAE}$에서 sample한 값.
- $p_{DAE}$는 hyperparameter이다.
- $\alpha_0=1$이다.(당연히… Y로부터 받는 input이 없으니까..)
Distillation
- Non-autoregressive sequence model에서 distillation이 중요하다고 밝혀짐.
- Distillation이 무엇인가는 요거 보면 대충 된다!
Length Prediction
- $p(T \vert X)$가 필요함.
- 그냥 training data의 target sequence length를 쓰도록 함
3.4 Inference
- Inference는 한번에 모든 스텝을 뽑고, 이를 iteration 돌리는 작업..

- 그러면 언제 Iteration을 멈출까?
- 사전에 정의한 criterion을 만족하면..
- target sequence가 얼마나 바뀌는지,
- conditional log-prob이 얼마나 바뀌는지,
- 계산할 시간에 따라…
- 사전에 정의한 criterion을 만족하면..
- 맨 처음께 제일 그럴싸한 방법이라고 한다. 실험에 나온다고…
4, Related Work
- 이거는 그냥 넘어가자..
- Parallel Wavenet - IAF를 썼는데, 이는 요 논문의 방법이랑 비슷하다고 하네..
- 근데 이거는 continuous space에서만 가능하다고 깐다..
- Deliberation networks: Sequence generation beyond one-pass decoding
- 요건 2step 짜리고, 2개의 autoregressive decoder를 가지고있다.
5. Network Architecture
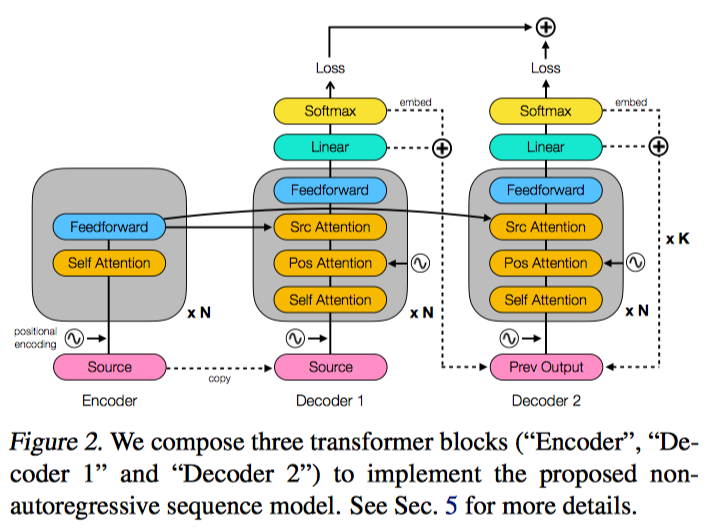
- Encoder는 Original transformer와 같다.
- Decoder 1은 $log\ p(Y^0 \vert X)$
- Decoder 2는 $log\ p(Y^l \vert \hat{Y}^{l-1}, X)$
- 을 모델링한 것!
- Decoder 2는 iterative refinement step에 계속 공유가 된다.
- Decoder에는 additional positional embedding이 들어간다.
6. Experimental Settings
- NMT와 Image Caption Generation에 대한 실험을 해봤음
- Target length prediction
- NA network training시에는 안쓰이고, 따로 training했으며, decoding시에만 사용
- Training and Inference
- L = 3으로 트레이닝하고, Adam썼음
- $p_{DAE} = 0.5$
- 다음 output이 이전과 똑같을 때까지 iteration돌리는 방법 - adaptive
7. Results and Analysis
7.1 Quantitative Analysis
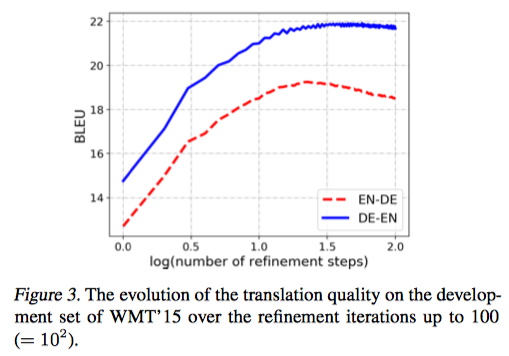
- 학습 시, iteration 4까지로 제한했는데도, decoding 시, iteration을 늘리면 결과가 더 좋음
- conditional DAE로 가정한 것을 뒷받침해준다.
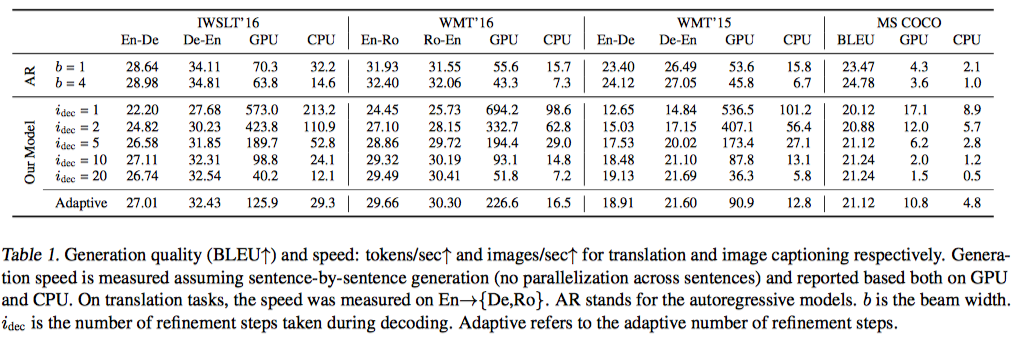
- quality <-> speed trade- off
- WMT-15 EN-DE에서 퀄리티가 떨어짐
- 다른 셋에 비해 length가 길다
- 자세한 설명은 없고 나중에 조사한다네..
- Image caption은 잘된다고 한다.
Decoding Latency
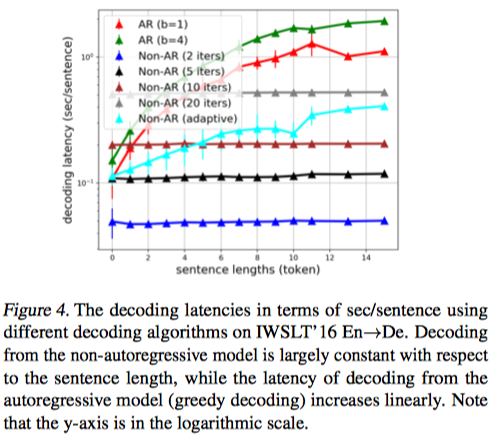
- log scale인 그림이다. 헷갈리지 말자
- AR은 sentence length에 따라 증가하는 반면,
- Non-AR은 모두 시간이 같다.
- Adaptive의 경우는 물론 증가하지만 AR보다는 적게 증가한다.
7.2 Ablation Study
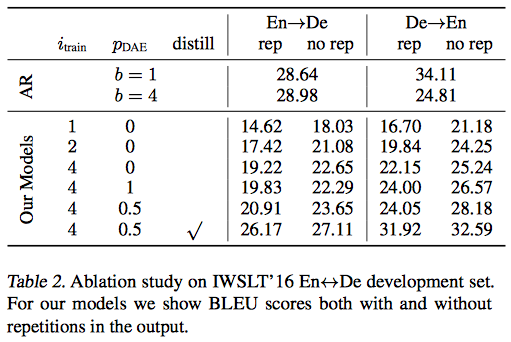
- model의 각 요소들이 얼마나 성능에 영향을 끼치는지 조사.
- distillation이 엄청 중요했다고 한다.
- inference시
- postprocessing으로 연속하는 반복된 symbol들을 제거하면 성능이 많이 좋아졌다.
- 역시 논문에 자주 쓰이는
나중에 조사해보겠다...
7.3 Qualitative Analysis
- NMT

- iteration마다 단조증가로 좋아지지는 않지만 좋아진다..
- Image Caption
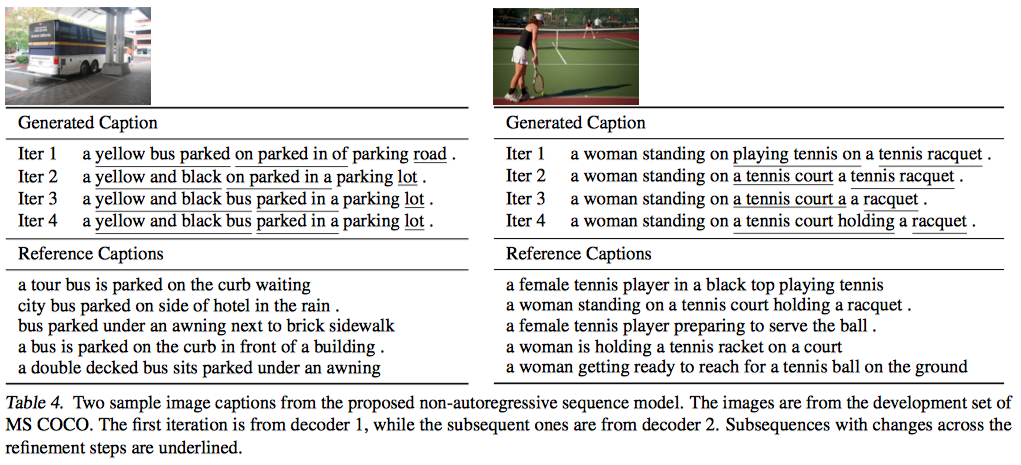
- 점점 묘사가 좋아진다고 함.
8. Conclusion
- 앞에 한 얘기 또 나오는 것은 정리하지 말자
- deterministic lower bound를 더 tight하게 구하면 좋을 것이다.
- corruption process를 좀 더 잘 만들면 좋을 것이다.