RL ch 5. Grid world & Neural network approximation
19 Mar 2018
|
ml
rl
PG
sarsa
강화학습 심화 1: Gridworld & Neural network approximation
- 책과 제목을 좀 바꿨는데… 근사함수보다는 NN을 쓰는 것을 강조하고싶었음..
- 현재까지 문제는
- state, action이 작고 변하지 않음
- 그래서 table로 저장해서 풀기 수월함
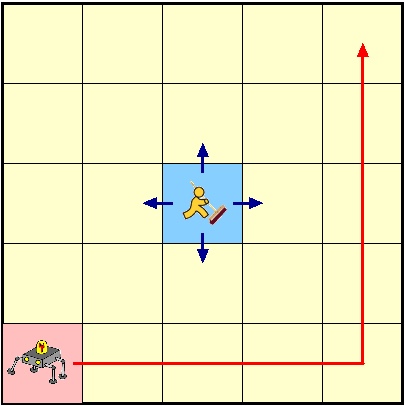
- 만약에 state, action space가 크거나, 변한다면?
- 근사함수
- state -> value 또는
- state -> policy 함수를 만들면 환경이 변해도 학습이 가능!
근사 함수
- review
- prediction
- MC: scenario sampling을 통해 학습
- TD: scenario의 중간 node들을 통해 학습
- control
- Sarsa: on-policy로 학습
- Q-learning: off-policy로 학습
- 위에 것 모두 model-free
- 즉, 환경에 대한 완벽한 정보가 필요하지 않음
- 모두 table기반의 강화학습
- state나 action이 많아지면 저장할 것도 많고… 이래저래 힘듬
- 그래서 근사함수가 필요!
딥살사
- SARSA
- $Q(S_t, A_t) \leftarrow Q(S_t, A_t) + \alpha(R_{t+1} + \gamma Q(S_{t+1}, A_{t+1}) - Q(S_t, A_t) )$
- 위의 수식을 구하는데, $q(s,a)$를 NN을 사용해서 근사시켜보자!
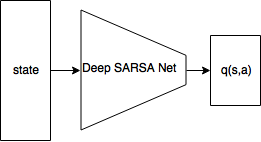
- 모든 action에 대해서 q(s,a)가 뽑힌다.
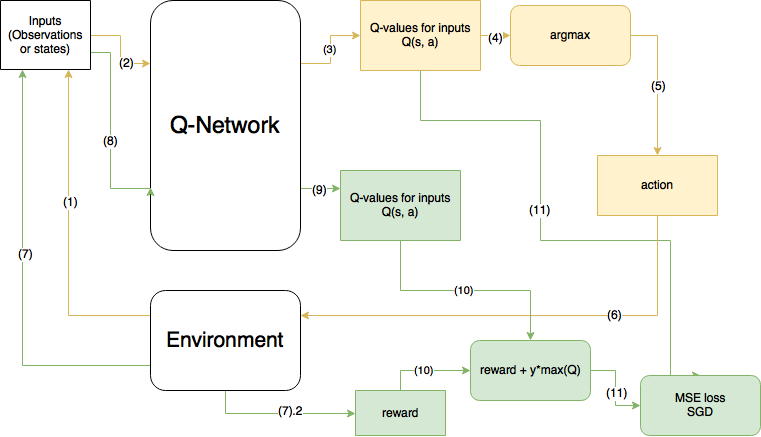
전체 구조
- 노란색이 현 step, 초록색이 다음 step을 의미한다.
Policy Gradient
- 여태까지 배운 알고리즘은 Value-based RL.
- 가치를 배우는 것이고, 가치 기반으로 행동을 선택
- PG는 Policy-based RL
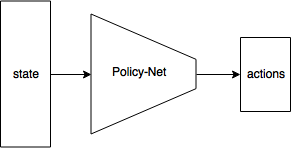
- $J(\theta) = v_{\pi_\theta}(s_0)$ 를 maximize
- 처음 상태 $s_0$에서의 Value func.를 최대화시키는 policy
-
-
- 보상이 마이너스면, 해당 정책을 낼 확률이 줄어들고,
- 보상이 플러스면 늘어남