
RL ch 6. DQN & Actor-critic
26 Mar 2018 | ml rl Actor-critic DQNDeep SARSA -> DQN
deep sarsa에서 DQN으로 넘어갈 때 추가된 것들을 정리…
- Experience replay
- target-network
Experience replay memory
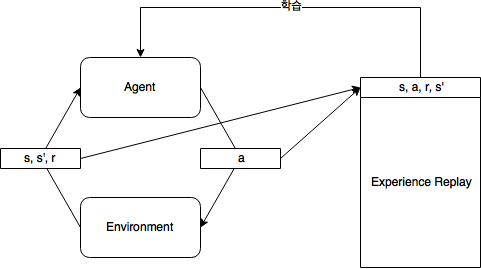
s,a,r,s'를 저장해놓고, 학습 시 임의로 셔플링해서 쓰는 방식- 이걸 쓰지 않으면 한 시나리오에 대해서 많은 학습 데이터가 들어오는데, 문제가 생김
- ex> 마리오 게임 2탄을 깨는 것을 학습하다가 1탄 깨는 것을 까먹음…
- iid한 data를 얻기위해…
- Deep sarsa는 on-policy니까 못쓰겠지…?
target-network
- DQN 수식
- Q(S,A)가 network로부터 나옴
- 정답이 계속 변하면 부트스트랩 문제가 더 심해짐
- target-network를 똑같이 만들어서 일정기간 유지시키자!
Actor-critic
- $ \theta_{t+1} = \theta_t + \alpha \cdot [\nabla_\theta log\pi_\theta(a \vert s) \cdot q_\pi(s, a)] $
- PG review
- 위에서 $q_\pi(s, a)]$를 시나리오에서 받는 보상으로…
- $ \theta_{t+1} = \theta_t + \alpha \cdot [\nabla_\theta log\pi_\theta(a \vert s) \cdot G_t] $
- $q_\pi(s, a)]$도 네트워크로 근사시키면 됨! <– critic network
- 기존의 action 내보내는 네트워크 <– actor
- 그래서 actor-critic
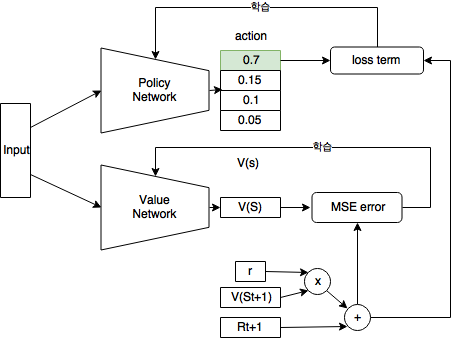
Baseline ( Advantage Actor-critic A2C)
- $ \theta_{t+1} = \theta_t + \alpha \cdot [\nabla_\theta log\pi_\theta(a \vert s) \cdot Q_w(s, a)] $
- 큐함수가 그대로 쓰이면 분산이 큼
- 베이스라인($V_v$) 사용
- $A(S_t, A_t) = Q_w(S_t,A_t) - V_v(S_t)$
- 이러면 $Q_w$와 $V_v$ 둘 다 근사함수를 만들어야함…
- $\delta_v = R_{t+1}+\gamma V_v(S_{t+1}) - V_v(S_t)$
- 요러면 해결!
- $ \theta_{t+1} = \theta_t + \alpha \cdot [\nabla_\theta log\pi_\theta(a \vert s) \cdot \delta_v] $
- 단점
- 현재 sample에 초점이 맞춰짐
- DQN보다 수렴이 느림
- 현재 sample에 초점이 맞춰짐
- critic update시 sarsa 방식을 사용
- off-plicy 학습 불가능…
- A3C