
tensorflow-js로 만들어본 RL 예제: 2. Deep-sarsa
14 Jun 2018 | ml rl Deep sarsa DQNDeep sarsa Demo
Deep Sarsa
Player
Goal
Obstacle
epsilon: 1.0
random action
action from network
refresh rate:
데모를 먼저 보이는데, 아마 이 글을 다 읽고, 올라와서 봐도 학습이 안되어있을지도 모른다…
tensorflow js가 느린 것 같기도…
Review
예전의 글에서 사진만 가져와서 살펴보면…
- 노란색이 현 step, 초록색이 다음 step을 의미한다.
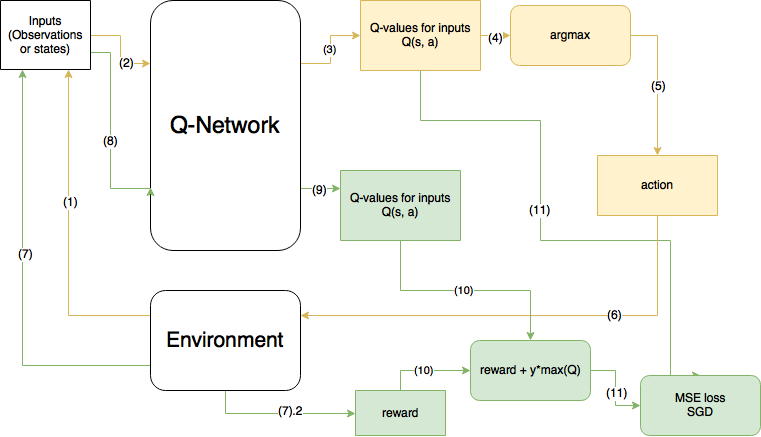
- 이 그림은 DQN이며, 사실은 10번 계산에서 max(Q)가 아니라 prediction한 action의 Q값이 들어가야한다.
Code
대략적인 코드를 살펴보면 다음과 같다.
function train(agent) {
for (var i_ep=0; i_ep < num_ep ; i_ep++){
env.initializeGame();
data = env.data
while (!done) {
action = agent.get_action(state) //(1)
next_state, reward, done = env.step(translateAction(action)) //(2)
next_action = agent.get_action(next_state) //(3)
agent.train_model(state, action, reward, next_state, next_action, done)//(4)
state = next_state
score += reward
}
}
}
- state에 대한 action을 얻는다. (물론 epsilon에 따라서 랜덤한 액션이 나올 수 있다.)
- 다음 state와 reward, done을 environment에서 얻는다.
- 다음 state에 대한 다음 action을 얻는다.
- 위에 얻은 정보를 취합하여 model을 학습시킨다.
이제 4번의 train_model함수를 보면 다음과 같다.
train_model(state, action, reward, next_state, next_action, done) {
if (this.epsilon > this.epsilon_min) { //(1)
this.epsilon *= this.epsilon_decay
}
q_res = this.model.predict(state) //(2)
target_reward = this.model.predict(next_state) //(3)
target_reward = target_reward[next_action] //(4)
if (done){ //(5)
q_res[action] = reward
}
else {
q_res[action] = reward + this.discount_factor * target_reward
}
this.model.fit(state, q_res, {epoch: 1}) //(6)
}
- epsilon 값을 점점 줄인다.
- model에서 $Q(s_t,a_t)$를 뽑는다.
- model에서 $Q(s_{t+1}, a_{t+1})$를 뽑는다
- $Q(s_{t+1}, a_{t+1})$에서 next action에 해당하는 부분을 다음 reward로 생각
- bellman 방정식에 맞게 계산하고..
- mse로 학습하면 끝!