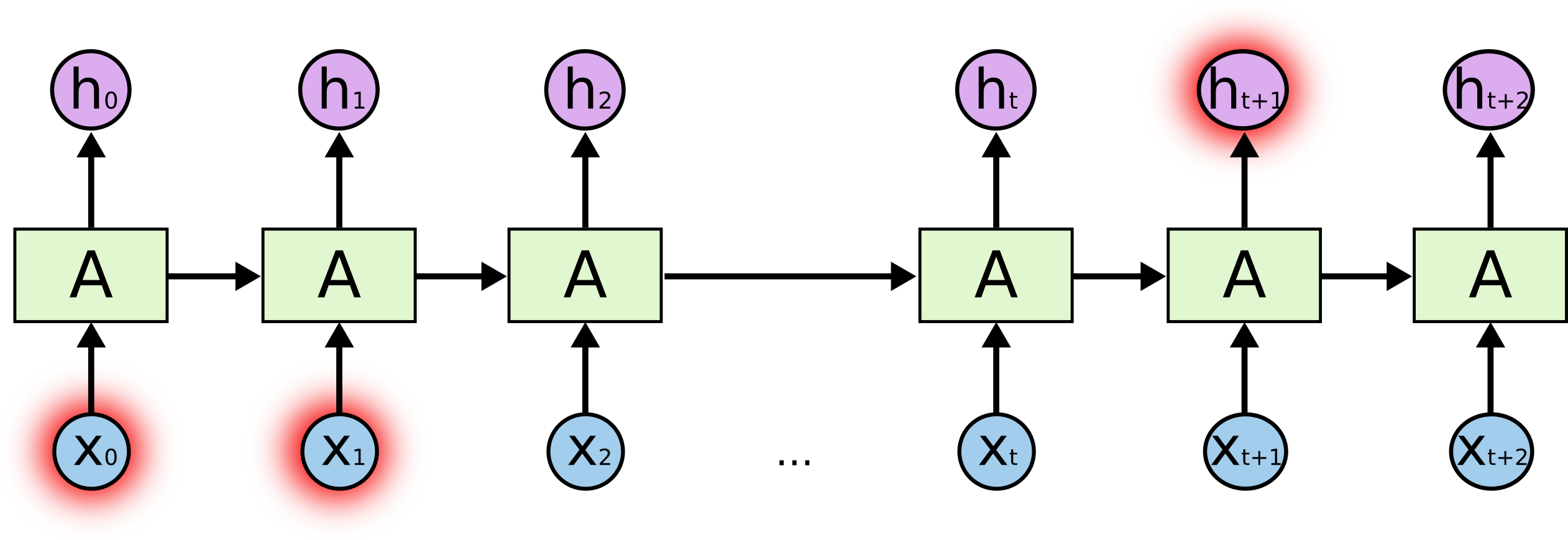
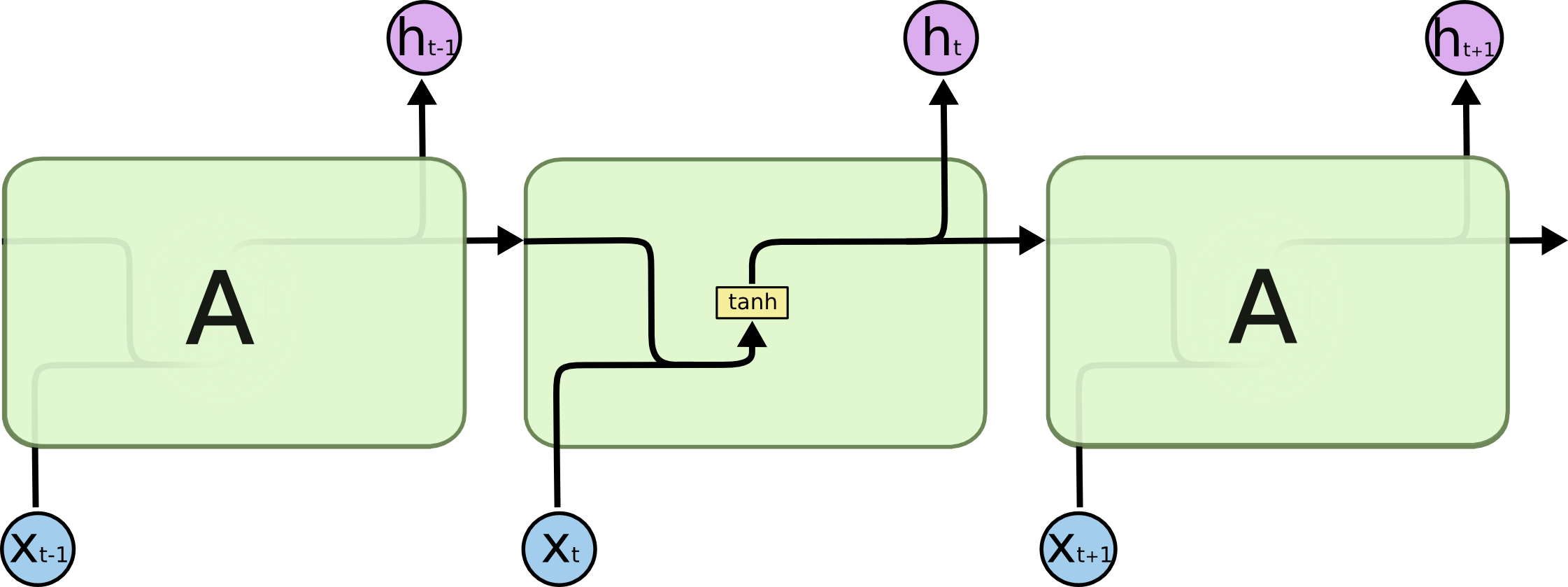
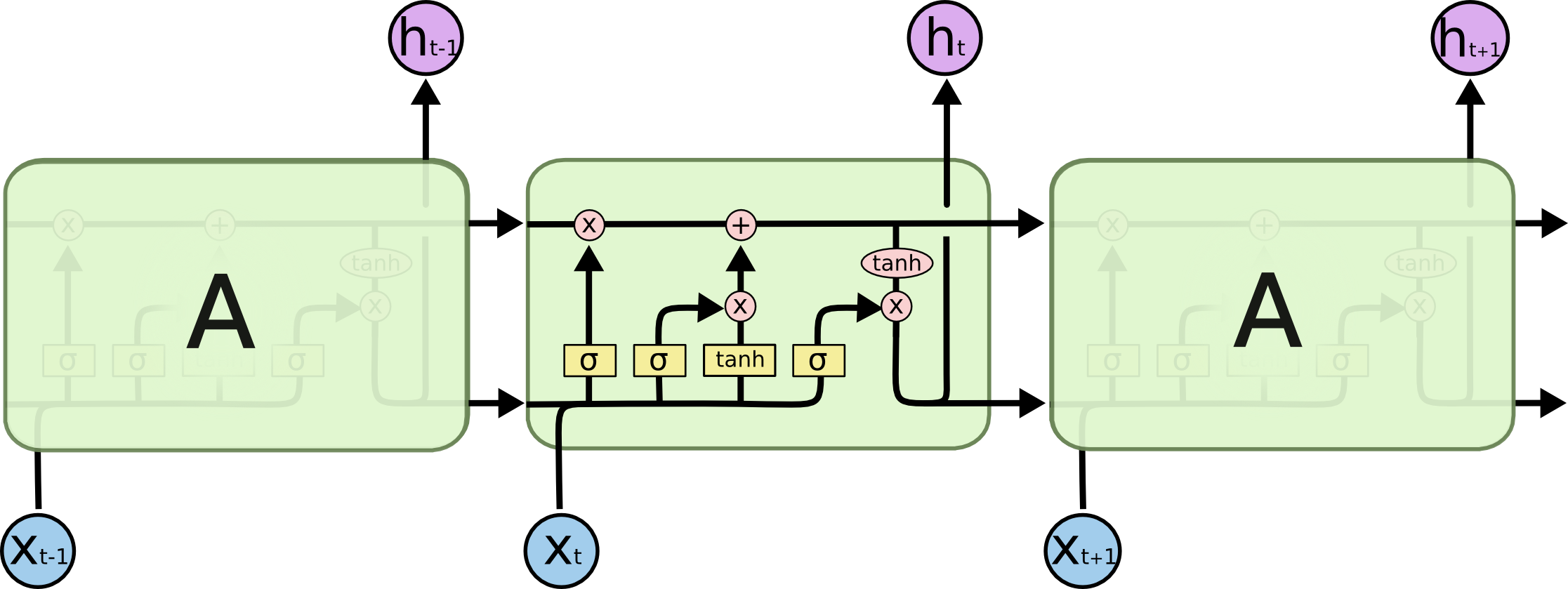
원문
Attention Mechanism
2015년 딥러닝과 AI의 진보에 따라, 많은 연구자들이 뉴럴넷의 <<attention mechanism>>에 관심을 가지고있다. 이 포스트는 어텐션 메카니즘이 무엇인지 high-level의 설명을 주는 것이 목표이며, 또한 attention의 계산에 관한 기술적인 몇가지 스텝들을 소개할 것이다.
만약 더 많은 수식과 예제를 원한다면 reference가 더 많은 디테일한 정보를 줄 것이다. [3] 불행하게도, 이러한 모델들은 항상 구현이 쉽지는 않고 몇개의 오픈소스로 된 구현들이 릴리즈되어있다.
Attention
attention을 포함한 neural process들은 신경과학과 Computational Neuroscience(뇌의 기능을 연구한다는데 적절한 단어를 모르겠네요..) 분야에서 연구되고 있었다. 특정 연구분야는 visual attention가 있다: 많은 동물들이 적절한 반응을 계산하기 위해 영상 신호에 대해 일부분만 집중한다. 이 원칙은 neural computation에서 큰 영향을 가져왔다.[정보를 모두 쓰기보다는 일부분만 가져와야했기 때문에] 입력값의 특정 부분에 집중하는 비슷한 아이디어가 딥러닝에 도 적용이 되어있다.[음성 인식, 번역, 추론(?), 물체 인식]
Attention for Image Captioning
이제 attention mechanism의 예제를 보자. 우리가 하고픈 일은 image captioning이다.
예전 image captioning system은 미리 학습한 CNN[hidden state h를 내는]을 이용해 image를 encode했다. 그리고는 그 state를 RNN을 써서 decode한다. 재귀적으로 caption을 생성한다. 이런 method는 [11]을 포함한 몇몇 그룹들이 사용했다. (아래 그림을 보라)

문제는 [모델이 자막의 다음 단어를 생성할 때, 이 단어는 보통 이미지의 일부분만을 묘사한다는] 것이다. (의역) 이미지의 전체 representation h를 사용하면 각 단어들을 효과적으로 생성할 수 없다. 이럴 때 attention mechanism이 도움이 된다.
attention mechanism을 사용하면, 이미지는 n개의 부분으로 나뉘어지고, CNN[각 파트에 대한 표현 $h_1,…,h_n$을 생성하는]을 거친다. RNN이 새로운 단어를 생성할 때, attention mechanism이 이미지의 연관된 부분에 집중하고, decoder는 이미지의 특정 부분만을 사용한다.
아래 이미지의 윗쪽 열에서, 각 단어에 대해 어떤 이미지(하얀색)가 사용되었는지 알 수 있다.

다른 예제로, 이미지의 어떤 부분이 밑줄친 단어를 생성하는데 쓰였는지 볼 수 있다.

이제 attention model이 어떻게 동작하는지 설명할 차례이다[일반적인 설정에서]. 복잡한건 [3]을 가보라.
attention model이 뭐에요?
어텐션 모델은 무엇일까?
 어텐션 모델은 방법[n개의 인자 $y_1,…,y_n$와 context $c$를 받아서 vector $z$를 내는]이다. 이 때, $z$는 $y_i$의 summary[c와 연관된 정보를 집중하는]로 생각된다. 더 formmal하게, 어텐션 모델은 yi의 weighted arithmetic mean을 반환하며, weight는 주어진 context c에 대한 각 $y_i$의 연관도에 따라 설정된다.
어텐션 모델은 방법[n개의 인자 $y_1,…,y_n$와 context $c$를 받아서 vector $z$를 내는]이다. 이 때, $z$는 $y_i$의 summary[c와 연관된 정보를 집중하는]로 생각된다. 더 formmal하게, 어텐션 모델은 yi의 weighted arithmetic mean을 반환하며, weight는 주어진 context c에 대한 각 $y_i$의 연관도에 따라 설정된다.
앞서 설명한 예제에서, context는 생성된 문장의 처음을 말하여, $y_i$는 각 이미지 부분들의 표현($h_i$)이고, output은 filtered image의 표현이다. 이 때, filter는 생성된 단어가 관심있는 부분을 포커싱한 것을 말한다.
attention model의 한가지 흥미로운 특징은 산술평균의 weight가 접근가능하며 plot이 가능하다는 것이다. 이는 앞서 본 이미지에서 하얀 색으로 색칠된 부분과 일치한다.
그래서 이 블랙박스가 정확히 어떻게 동작하나? attention model의 전체 그림은 다음과 같다.

네트워크가 복잡해보이는데 차근차근 설명할테니 걱정마시라.
먼저 입력부터 살펴보자. c는 context, y_i는 데이터의 일부분이다.

다음 스텝으로, 네트워크는 $m_1, …, m_n$을 계산[tanh 레이어를 통해]하는데 이는 c와 y_i의 값의 집단을 계산하는 것을 의미한다. 여기서 $m_i$를 계산할 때, $y_i$만 보고 다른 $y$는 보지 않는다.

이제 softmax를 계산한다. softmax는 argmax와 비슷한 양상을 보이지만, 미분이 가능하다. (softmax 설명 생략)
 이제 $s_i$와 $y_i$를 곱해서 모두 더하면 output z가 나오게 된다.
이제 $s_i$와 $y_i$를 곱해서 모두 더하면 output z가 나오게 된다.

relevance의 다른 계산법
위에 설명한 attention model은 변경 가능하다. 먼저 tanh를 바꿔볼 수 있다. 딱 한가지 중요한 것은 c와 y_i를 믹싱하는 함수라는 것이다. 여기서 사용한 것은 c와 y_i의 dot product이다.

이 모델이 더 이해하기 쉬운데, context와 가장 관련 깊은 변수를 softly-choosing한다는 것이다. 다른 중요한 버전은 hard attention이다.
soft attention & hard attention
위에 보여준 메카니즘을 soft attention이라 부른다. 왜냐면 전부 미분가능하며, attention mechanism을 통해 gradient가 흘러갈 수 있기 때문이다.(의역)
hard attention은 stochastic process이다: 모든 hidden state들을 decoding의 input으로 쓰는 대신에, hidden state $y_i$를 확률 $s_i$로 샘플링해서 쓴다. gradient를 구하기 위해서는 몬테카를로 sampling으로 gradient를 추정해야한다.

두 시스템 모드 장단점이 있는데, 현재는 gradient를 직접적으로 계산할 수 있는 soft attention을 더 많이쓴다.
image captioning으로 돌아가보자!
이제 앞서 보인 image captioning system이 어떻게 동작하는지 이해가 가능할 것이다.

(그림에 대한 설명 생략)
기계 번역에서의 align
Bahdanau[5]가 제안한 neural translation model도 attention을 쓰고있다.
먼저 attention을 쓰지 않은 신경망 번역을 보자. encoder[RNN을 쓰는]는 영어 문장을 입력으로 받아서 hidden state h를 제공한다. 이 hidden state h는 decoder RNN이 옳은 output 프랑스 문장을 만들도록 조정한다.

번역에서, image captioning과 같은 생각을 할 수 있다. 새로운 단어를 만들 때, 우리는 보통 원문에 있는 하나의 단어를 번역한다. attention model은 새로운 단어를 만들 때, 원문의 일부분에 집중하도록 만들어준다.

전체 문장에 대한 단 하나의 hidden state를 제공하는 대신, incoder는 각 단어에 해당하는 hidden state $h_j$를 제공한다. decoder RNN이 단어를 생성할 때마다, 각 hidden state의 공헌도를 결정하고, 보통 그것은 하나의 state를 뽑는다.(밑의 그림을 보라) softmax를 사용한 공헌도는 attention weight $a_j$를 의미하며, hidden state $h_j$는 decoding에 weight $a_j$만큼 기여한다.
이 케이스에서, attention mecanism은 전부 미분가능하며, 다른 supervision을 필요치않는다. 그저 Encoder-decoder 모델의 위에 추가된 것이다.
이 방식은 alignment라고도 볼 수 있는데, 네트워크가 새 단어를 만들어내는 매 스텝마다 보통 하나의 input 단어에 집중하기 때문이다. 이것은 거의 대부분의 weight가 0이며, 하나의 weight만 활성화됨을 의미한다. 밑의 그림은 번역 중의 attention weight를 보여준다.

RNN이 없는 attention
여태까지 encoder-decoder에 들어간 attention model만 설명했다. 그러나, input의 순서는 중요하지 않으려, 독립된 hidden states $h_j$에 대해서도 가능하다. (의역)Raffel[10]의 경우가 그러한데 attention model이 fully feed-forward이며, memory-network의 간단한 예시에서도 드러난다.
from attention to memory addressing
이 부분은 생략…
##Final word
attention mechanism과 fully differentiable addressable memory system은 현재 많은 연구자들이 연구중이다. 아직 나온지 얼마 안되고, 구현이 덜 되었음에도, 이것이 많은 문제들의 state of the art를 달성하는 것을 보여주었다.
이후도 생략…